如何使用交互式 Spark 作业优化 Spark 集群

在本文中,您将了解:
- 如何缩短 Spark 作业执行时间
- 什么是 Ilum 中的交互式工作
- 如何运行交互式 Spark 作业
- 使用 Ilum API 和 Spark API 运行 Spark 作业之间的区别
Ilum 作业类型
您可以在 Ilum 中运行三种类型的作业: 单个作业 , 交互式作业 和 交互式代码 .在本文中,我们将重点介绍 交互式作业 类型。但是,了解这三种工作之间的区别很重要,因此让我们快速了解一下每一种。
跟 单个作业 中,您可以提交类似代码的程序。它们允许您使用预编译的代码将 Spark 应用程序提交到集群,而无需在运行时进行交互。在此模式下,您必须将编译后的 jar 发送到 Ilum,该 jar 用于启动单个作业。您可以直接发送它,也可以使用 AWS 凭证从 S3 存储桶获取它。单个作业使用的典型示例是某种数据准备任务。
Ilum 还提供了一个 互动 代码模式 ,它允许您在运行时提交命令。这对于需要与数据交互的任务(例如探索性数据分析)非常有用。
交互式作业
交互式作业具有长时间运行的会话,您可以在其中发送要立即执行的作业实例数据。这种模式的杀手锏是你不必等待 spark 上下文初始化。如果用户指向相同的作业 ID,他们将与相同的 Spark 上下文进行交互。Ilum 将 Spark 应用程序逻辑包装到长时间运行的 Spark 作业中,该作业能够立即处理计算请求,而无需等待 Spark 上下文初始化。
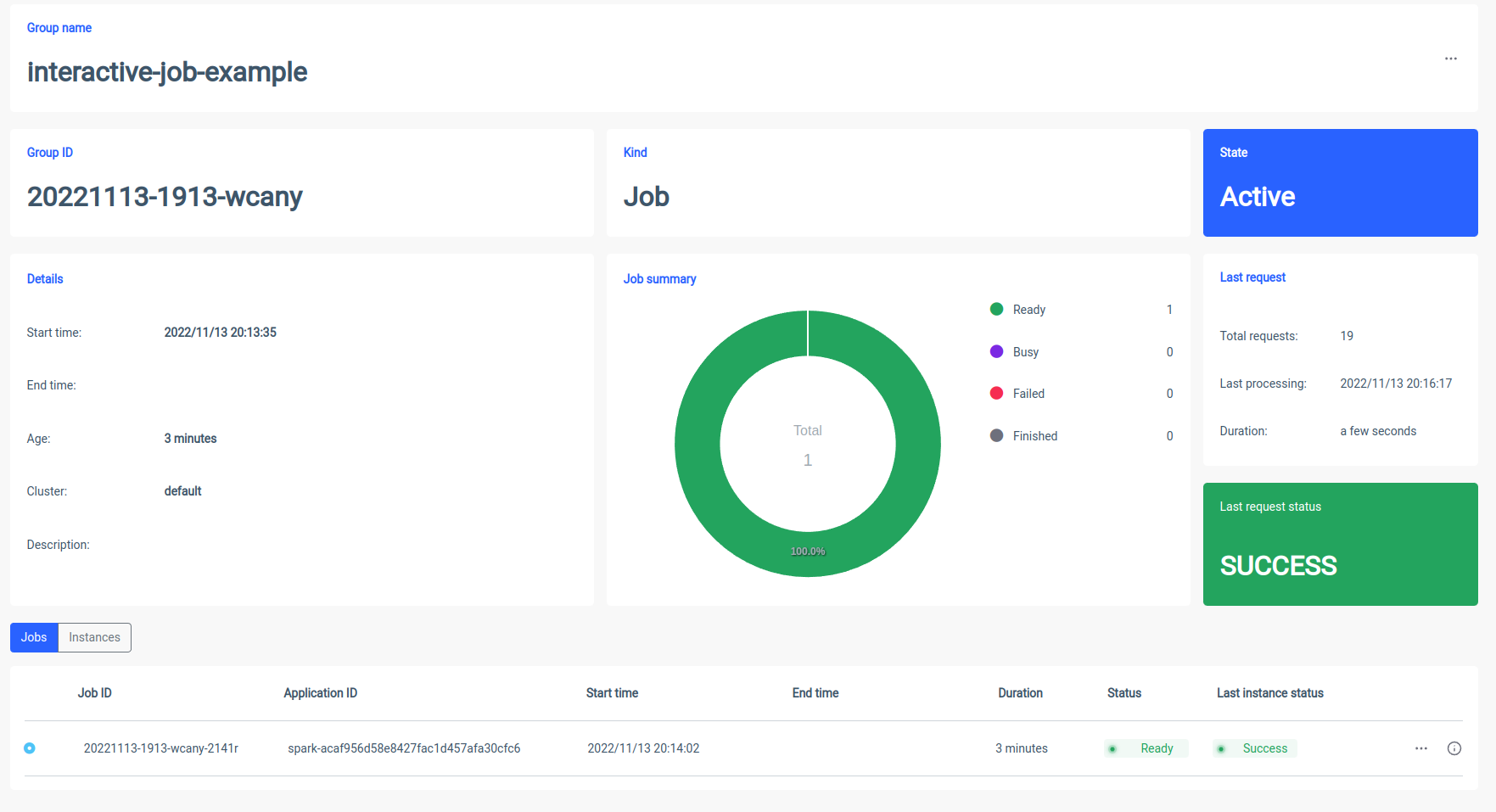
启动交互式作业
让我们来看看如何启动 Ilum 的交互式会话。我们要做的第一件事是设置 Ilum。您可以使用 minikube 轻松完成。在此下提供了 Ilum 安装教程 链接 .在下一步中,我们必须创建一个 jar 文件,其中包含 Ilum 作业接口的实现。要使用 Ilum 作业 API,我们必须将其添加到具有一些依赖项管理器(例如 Maven 或 Gradle)的项目中。在此示例中,我们将使用一些带有 Gradle 的 Scala 代码来计算 PI。
完整的示例可在我们的 GitHub的 .
如果您不想自己构建它,您可以找到编译后的 jar 文件 这里 .
第一步是为我们的项目创建一个文件夹,并将目录更改为该文件夹。
$ mkdir interactive-job-example
$ cd 交互式作业示例 如果您的计算机上没有安装最新版本的 Gradle,您可以检查如何作 这里 .然后在终端中从项目目录内运行以下命令:
$ gradle 初始化 选择以 Groovy 作为 DSL 的 Scala 应用程序。输出应如下所示:
启动 Gradle 守护进程(后续构建会更快)
选择要生成的项目类型:
1:基本
2:应用
3:库
4:Gradle 插件
输入选择 (默认: 基本) [1..4] 2
选择实现语言:
1:C++
2:时髦
3:爪哇
4:科特林
5:Scala
6:斯威夫特
输入选择(默认值:Java)[1..6] 5
跨多个子项目拆分功能?:
1:否 - 只有一个应用程序项目
2:是 - 应用程序和库项目
输入选择 (默认值: 否 - 只有一个应用程序项目) [1..2] 1
选择 build script DSL:
1:时髦
2:科特林
输入选择 (默认: Groovy) [1..2] 1
使用新的 API 和行为生成生成版本(某些功能可能会在下一个次要版本中更改)?(默认值:否)[是,否] 否
项目名称(默认:interactive-job-example):
源码包(默认:interactive.job.example):
> 任务 :init
获取有关项目的更多帮助:https://docs.gradle.org/7.5.1/samples/sample_building_scala_applications_multi_project.html
在 30 秒内构建成功
2 个可作任务:2 个已执行 现在我们必须将 Ilum 存储库和必要的依赖项添加到您的 build.gradle 文件。在本教程中,我们将使用 Scala 2.12。
依赖项 {
实现 'org.scala-lang:scala-library:2.12.16'
实现 'cloud.ilum:ilum-job-api:5.0.1'
编译仅 'org.apache.spark:spark-sql_2.12:3.1.2'
} 现在我们可以创建一个 Scala 类来扩展 Ilum 的 Job 并计算 PI:
包 interactive.job.example
导入 cloud.ilum.job.Job
导入 org.apache.spark.sql.SparkSession
导入 scala.math.random
class InteractiveJobExample extends Job {
override def run(sparkSession: SparkSession, config: Map[String, Any]): Option[String] = {
val slices = config.getOrElse(“slices”, “2”).toString.toInt
val n = math.min(100000L * 切片,Int.MaxValue).toInt
val count = sparkSession.sparkContext.parallelize(1 until n, slices).map { i =>
值 x = 随机 * 2 - 1
值 y = 随机 * 2 - 1
if (x * x + y * y <= 1) 1 else 0
}.reduce(_ + _)
Some(s“Pi 大约是 ${4.0 * count / (n - 1)}”)
}
} 如果 Gradle 生成了一些 main 或 test 类,只需将它们从项目中删除并进行构建即可。
$ gradle 构建 生成的 jar 文件应位于 ' ./interactive-job-example/app/build/libs/app.jar ',然后我们可以切换回 Ilum。所有 Pod 都运行后,请为 ilum-ui 进行端口转发:
kubectl 端口转发 svc/ilum-ui 9777:9777 在浏览器中打开 Ilum UI 并创建一个新组:
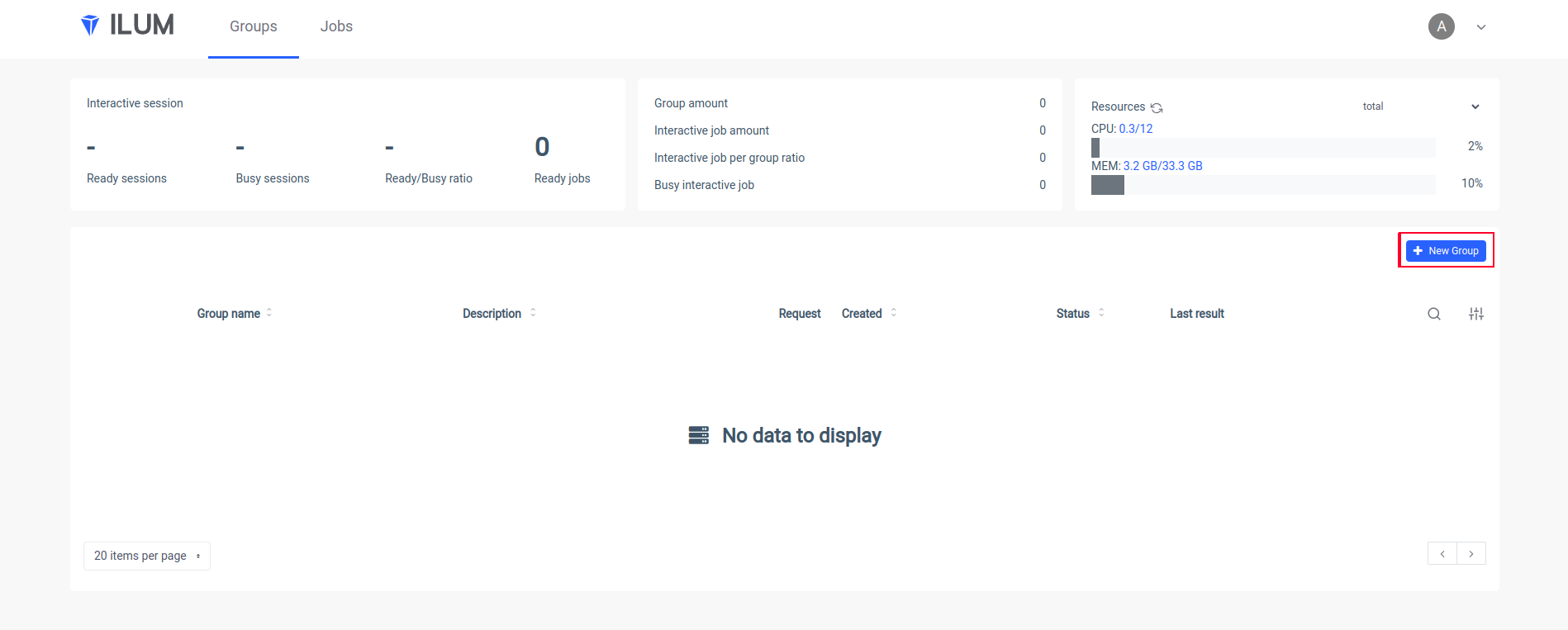
输入组的名称,选择或创建集群,上传 jar 文件并应用更改:
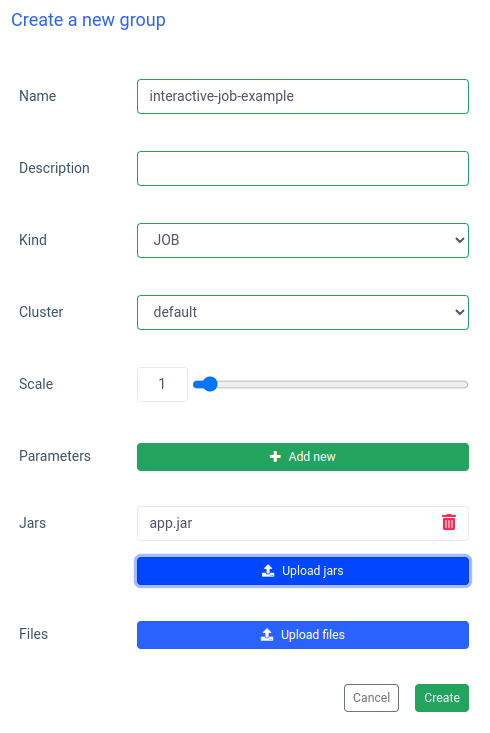
Ilum 将创建一个 Spark 驱动程序 Pod,您可以通过扩展 Spark 执行程序 Pod 来控制它们的数量。Spark 容器准备就绪后,让我们执行作业:
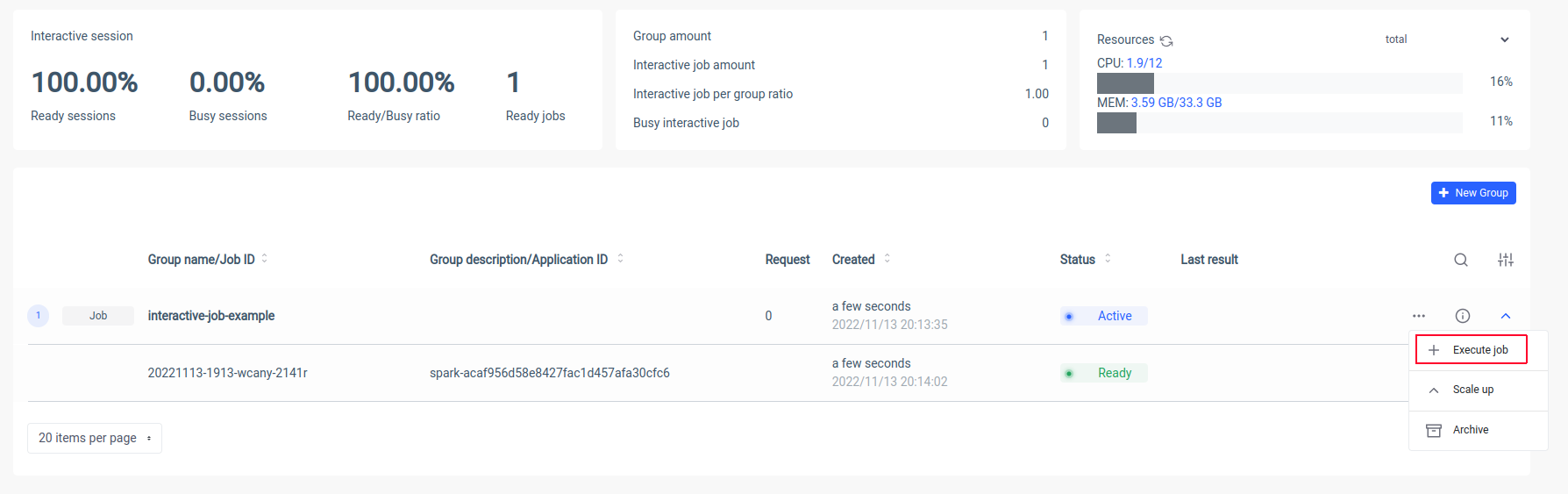
现在我们必须输入 Scala 类的规范名称
interactive.job.example.InteractiveJobExample 并以 JSON 格式定义 slices 参数:
{
“config”: {
“切片”: “10”
}
} 您应该在作业开始后立即看到结果
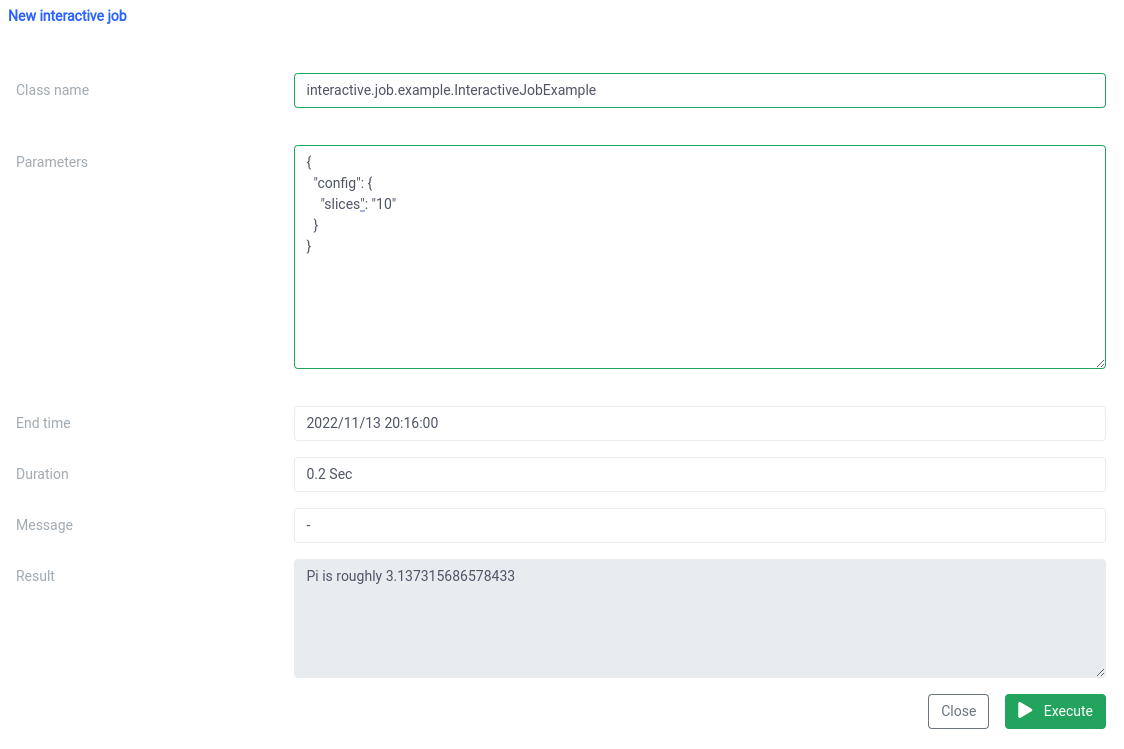
您可以更改参数并重新运行作业,您的计算将当场进行。
交互式和单个作业比较
在 Ilum 中,您还可以运行单个作业。与交互模式相比,最重要的区别是您不必实现 Job API。我们可以使用 Spark 示例中的 SparkPi jar:
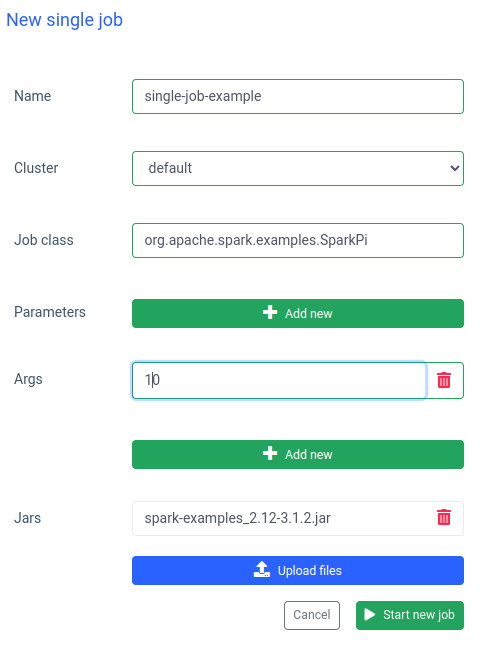
运行这样的作业也很快,但交互式作业 快 20 倍(4 秒 vs 200 毫秒) .如果要使用其他参数启动类似的作业,则必须准备新作业并再次上传 jar。
Ilum 和普通 Apache Spark 比较
我在本地使用 Bitnami/Spark docker 镜像。如果您还想在计算机上运行 Spark,则可以使用 docker-compose:
$ curl -LO https://raw.githubusercontent.com/bitnami/containers/main/bitnami/spark/docker-compose.yml
$ docker-compose up Spark 运行后,您应该能够转到 localhost:8080 并查看管理 UI。我们需要从浏览器获取 Spark URL:

然后,我们必须使用
$ docker exec -it <containerid> -- bash 
现在,在容器内,我们可以提交 sparkPi 作业。在本例中,将使用示例 jar 中的 SparkiPi,并将浏览器中的 URL 作为主参数:
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi\
--master spark://78c84485d233:7077 \
/opt/bitnami/spark/examples/jars/spark-examples_2.12-3.3.0.jar\
10 总结
如上例所示,您可以使用 Ilum 避免 Spark 客户端的复杂配置和安装。Ilum 接管了这项工作,并为您提供了一个简单方便的界面。此外,它还允许您克服 Apache Spark 的限制,这些限制可能需要很长时间才能初始化。如果您必须执行许多具有相似逻辑但参数不同的任务,并且希望立即完成计算,则绝对应该使用交互式任务模式。

与 Apache Livy 的相似之处
Ilum 是一种云原生工具,用于管理 Kubernetes 上的 Apache Spark 部署。它在功能方面类似于 Apache Livy - 它可以通过 REST API 控制 Spark 会话,并与 Spark 集群构建实时交互。但是,Ilum 是专为现代云原生环境设计的。
我们过去使用过 Apache Livy,但现在已经到了 Livy 不适合现代环境的地步。 Livy 已过时 与 Ilum 相比。2018 年,我们开始将所有环境迁移到 Kubernetes,我们必须找到一种方法来在 Kubernetes 上部署、监控和维护 Apache Spark。这是建立 Ilum 的最佳时机。