在 Kubernetes 上部署 PySpark 微服务:使用 Ilum 革新数据湖。

您好 Ilum 爱好者和 Python 粉丝!我们很高兴推出一项备受期待的新功能,它将为您的数据科学之旅提供支持 - Ilum 中的完整 Python 支持。对于数据世界的人来说,Python 和 Apache Spark 长期以来一直是标志性的组合,可以无缝处理大量数据和复杂的计算。现在,通过 Ilum 的最新升级,您可以直接在自己喜欢的数据湖环境中利用 Python 的强大功能。
这篇博文是您探索此功能的指导教程。我们将从一个用 Python 编写的简单 Apache Spark 作业开始,在 Ilum 上运行它,然后进行更深入的研究。我们将转换初始代码以支持交互模式,让您通过 Ilum 的 API 直接访问 Spark 作业。在此旅程结束时,您将拥有一个基于 Python 的微服务来响应 API 调用,所有这些都在 Ilum 上平稳运行。
那么,您准备好使用 Python 和 Ilum 增强您的数据游戏了吗?让我们开始吧。
所有示例都可以在我们的 GitHub 存储库 .
第 1 步:用 Python 编写一个简单的 Apache Spark 作业。
在我们与 Ilum 一起踏上 Python 之旅之前,我们需要确保我们的环境设备齐全。要运行 Spark 作业,您需要安装 Ilum 和 PySpark。您可以使用 pip(Python 软件包安装程序)来设置 PySpark。确保您使用的是 Python >=3.9。
pip 安装 pyspark 要设置和访问 Ilum,请遵循提供的指南 这里 .
1.1 SparkPi 示例。
现在,让我们开始编写 Spark 作业。我们将从 SparkPi 的一个简单示例开始
导入 SYS
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == “__main__”:
spark = SparkSession \
。建筑工人\
.appName(“PythonPi”) \
.getOrCreate()
partitions = int(sys.argv[1]) 如果 len(sys.argv) > 1 else 2
n = 100000 * 分区
def f(_: int) -> 浮点数:
x = 随机() * 2 - 1
y = 随机() * 2 - 1
返回 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print(“圆周率大约为 %f” % (4.0 * 计数 / n))
spark.stop() 将此脚本另存为 ilum_python_simple.py
Spark 作业准备就绪后,可以在 Ilum 上运行它。Ilum 提供了使用 Ilum UI 或通过 REST API 提交作业的功能。
让我们从 UI 开始,使用 Single Job 功能。
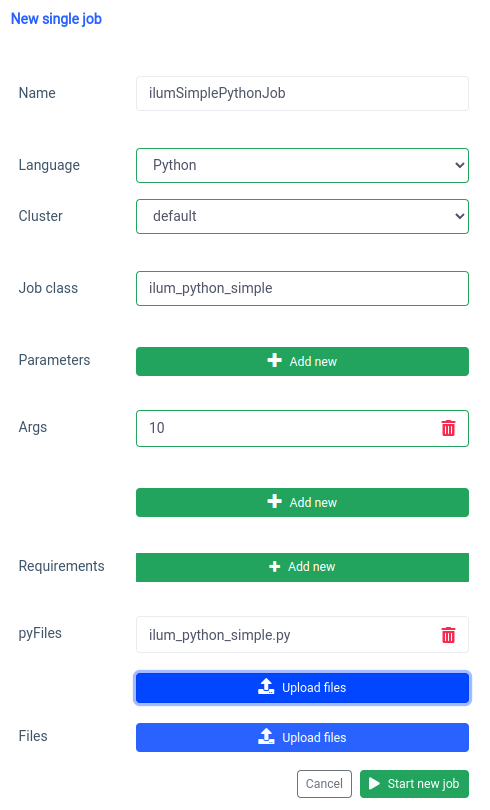
我们可以使用 应用程序接口 ,但首先,我们需要使用 port forward 公开 ilum-core API。
kubectl 端口转发 svc/ilum-core 9888:9888 使用公开的端口,我们可以进行 API 调用。
curl -X POST 'localhost:9888/api/v1/job/submit' \
--form 'name=“ilumSimplePythonJob”' \
--form 'clusterName=“default”' \
--form 'jobClass=“ilum_python_simple”' \
--form 'args=“10”' \
--form 'pyFiles=@“/path/to/ilum_python_simple.py”' \
--form 'language=“PYTHON”' API 调用
因此,我们将收到已创建作业的 ID。
{“jobId”:“20230724-1154-m78f3gmlo5j”} 结果
要检查作业的日志,我们可以对
curl 本地主机:9888/api/v1/job/20230724-1154-m78f3gmlo5j/logs API 调用
就是这样!您已经在 Ilum 上编写并运行了一个简单的 Python Spark 作业。让我们看一个更高级的示例,它需要额外的 Python 库。
1.2 使用 numpy 的作业示例。
在本节中,我们将介绍一个用 Python 编写的 Spark 作业的实际示例。这项工作包括读取数据集、处理数据集、在其上训练机器学习模型以及保存预测。我们将使用 Tel-churn.csv 文件,您可以在我们的 GitHub 存储库 .为方便起见,我们已将此文件上传到 MinIO 内置实例中名为 ilum-files 的存储桶中,该存储桶可从 Ilum 实例自动访问。这意味着您不必担心为此示例配置任何访问权限 - Ilum 已经涵盖了它。但是,如果您想从其他存储桶获取数据或在自己的项目中使用 Amazon S3,则需要相应地配置访问权限。
现在我们已经准备好了数据,让我们开始用 Python 编写 Spark 作业。以下是完整的代码示例:
from pyspark.sql import SparkSession
from pyspark.ml import 管道
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.classification import LogisticRegression
if __name__ == “__main__”:
spark = SparkSession \
。建筑工人\
.appName(“IlumAdvancedPythonExample”) \
.getOrCreate()
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True)
categoricalColumns = ['性别', '合作伙伴', '家属', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', '技术支持', 'StreamingTV',
'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod']
阶段 = []
对于 categoricalColumns 中的 categoricalCol:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + “索引”)
阶段 += [stringIndexer]
label_stringIdx = StringIndexer(inputCol=“Churn”, outputCol=“label”)
阶段 += [label_stringIdx]
numericCols = ['老年人', '任期', '每月收费']
assemblerInputs = [c + categoricalColumns 中 c 的“索引”] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol=“features”)
阶段 += [汇编器]
管道 = 管道(stages=stages)
管道模型 = pipeline.fit(df)
df = pipelineModel.transform(df)
train, test = df.randomSplit([0.7, 0.3], seed=42)
lr = LogisticRegression(featuresCol=“features”, labelCol=“label”, maxIter=10)
lrModel = lr.fit(train)
预测 = lrModel.transform(test)
predictions.select(“customerID”, “label”, “prediction”).show(5)
predictions.select(“customerID”, “label”, “prediction”).write.option(“header”, “true”) \
.csv('s3a://ilum-files/predictions')
spark.stop() 让我们深入研究代码:
from pyspark.sql import SparkSession
from pyspark.ml import 管道
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.classification import LogisticRegression 在这里,我们将导入必要的 PySpark 模块来创建 Spark 会话、构建机器学习管道、预处理数据并运行 Logistic 回归模型。
spark = SparkSession \
。建筑工人\
.appName(“IlumAdvancedPythonExample”) \
.getOrCreate() 我们初始化一个 SparkSession ,这是 Spark 中任何功能的入口点。在这里,我们设置将显示在 Spark Web UI 上的应用程序名称。
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True) 我们正在读取存储在 minio 存储桶上的 CSV 文件。这 header=真 option 指示 Spark 使用 CSV 文件的第一行作为标题,而 inferSchema=True 使 Spark 自动确定每列的数据类型。
categoricalColumns = ['性别', '合作伙伴', '家属', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', '技术支持', 'StreamingTV',
'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod'] 我们在数据中指定分类列。稍后将使用 StringIndexer 转换这些内容。
阶段 = []
对于 categoricalColumns 中的 categoricalCol:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + “索引”)
阶段 += [stringIndexer] 在这里,我们将迭代我们的分类列列表,并为每个列创建一个 StringIndexer。StringIndexer 将分类字符串列编码为索引列。转换后的索引列将命名为附加“Index”的原始列名。
numericCols = ['老年人', '任期', '每月收费']
assemblerInputs = [c + categoricalColumns 中 c 的“索引”] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol=“features”)
阶段 += [汇编器] 在这里,我们为机器学习模型准备数据。我们创建一个 VectorAssembler,它将获取我们所有的特征列(分类和数字)并将它们组装成一个向量列。这是 Spark 中大多数机器学习算法的要求。
train, test = df.randomSplit([0.7, 0.3], seed=42) 我们将数据分为训练集和测试集,其中 70% 的数据用于训练,其余 30% 用于测试。
lr = LogisticRegression(featuresCol=“features”, labelCol=“label”, maxIter=10)
lrModel = lr.fit(train) 我们根据训练数据训练 Logistic 回归模型。
预测 = lrModel.transform(test)
predictions.select(“customerID”, “label”, “prediction”).show(5)
predictions.select(“customerID”, “label”, “prediction”).write.option(“header”, “true”) \
.csv('s3a://ilum-files/predictions') 最后,我们使用经过训练的模型对测试集进行预测,显示前 5 个预测。然后,我们将这些预测写回我们的 minio 存储桶。
将此脚本另存为 ilum_python_advanced.py
pyspark.ml 使用 numpy 作为依赖项,它没有作为默认安装,因此我们需要将其指定为要求。
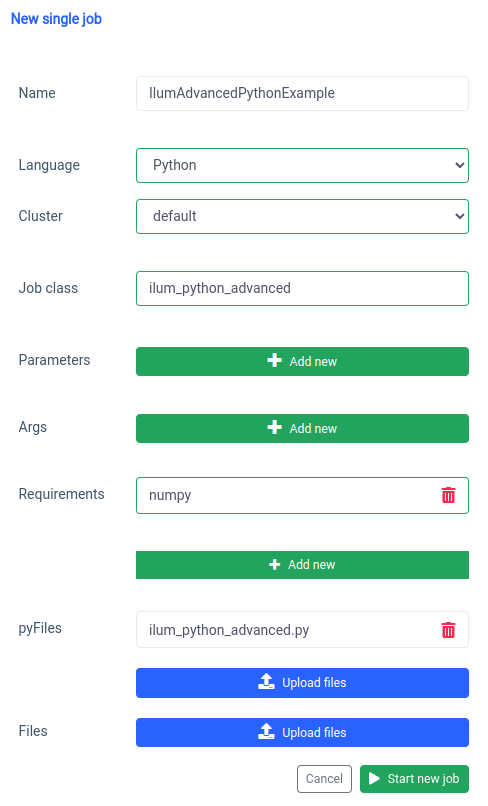
同样的事情也可以通过 API 来完成。
curl -X POST 'localhost:9888/api/v1/job/submit' \
--form 'name=“IlumAdvancedPythonExample”' \
--form 'clusterName=“default”' \
--form 'jobClass=“ilum_python_advanced”' \
--form 'pyRequirements=“numpy”' \
--form 'pyFiles=@“/path/to/ilum_python_advanced.py”' \
--form 'language=“PYTHON”' API 调用
在接下来的部分中,我们会将这两个 Python 脚本转换为 互动 Spark 作业,充分利用 Ilum 的功能。
第 2 步:过渡到交互模式
交互模式是一项令人兴奋的功能,它使 Spark 开发更加动态,使您能够实时运行、交互和控制 Spark 作业。它专为那些寻求更直接地控制其 Spark 应用程序的用户而设计。
将交互模式视为与您的 Spark 作业进行直接对话。您可以实时输入数据、请求转换和获取结果。这大大提高了数据处理管道的敏捷性和功能,使其更具适应性和响应能力,可以更好地响应不断变化的需求。
现在我们已经熟悉了如何在 Python 中创建基本的 Spark 作业,让我们更进一步,将我们的作业转换为可以利用 Ilum 实时功能的交互式作业。
2.1 SparkPi 示例。
为了说明如何将我们的作业转换为交互模式,我们将调整前面的 ilum_python_simple.py 脚本。
from random import random
from operator import add
from ilum.api import IlumJob
类 SparkPiInteractiveExample(IlumJob):
def run(self, spark, config):
分区 = int(config.get('partitions', '5'))
n = 100000 * 分区
def f(_: int) -> 浮点数:
x = 随机() * 2 - 1
y = 随机() * 2 - 1
返回 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
返回 “Pi 大约为 %f” % (4.0 * count / n) 将此 Save this as ilum_python_simple_interactive.py
与原始 SparkPi 只有一些不同。
1. Ilum 软件包
首先,我们将 IlumJob class 来获取 ilum 包,该包用作交互式作业的基类。
Spark 作业逻辑封装在一个类中,该类扩展了 IlumJob ,尤其是在其 跑 方法。我们可以添加 ilum 包:
pip 安装 ilum 2. 类中的 Spark 作业
Spark 作业逻辑封装在一个类中,该类扩展了 IlumJob ,尤其是在其 跑 方法。
类 SparkPiInteractiveExample(IlumJob):
def run(self, spark, config):
# Job logic 在这里 将作业逻辑包装在一个类中对于 Ilum 框架处理作业及其资源至关重要。这也使 Job 无状态且可重用。
3. 参数的处理方式不同:
我们从 config 字典中获取所有参数
分区 = int(config.get('partitions', '5')) 这种转变允许更动态的参数传递,并与 Ilum 的配置处理集成。
4. 返回结果而不是打印结果:
结果从 跑 方法。
返回 “Pi 大约为 %f” % (4.0 * count / n) 通过返回结果,Ilum 可以更灵活地处理它。例如,Ilum 可以序列化结果并使其可通过 API 调用进行访问。
5. 无需手动管理 Spark 会话
Ilum 为我们管理 Spark 会话。它会自动注入到 跑 方法,我们不需要手动停止它。
def run(self, spark, config): 这些更改突出显示了从独立 Spark 作业到交互式 Ilum 作业的过渡。目标是提高作业的灵活性和可重用性,使其更适合动态、交互式和动态计算。
添加交互式 Spark 作业是使用 'new group' 函数处理的。
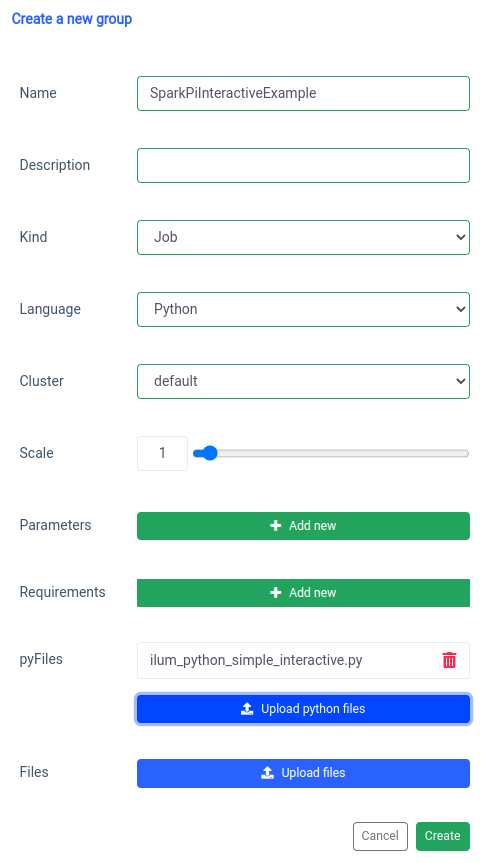
以及使用 UI 上的交互式工作函数执行。
类名应指定为 pythonFileName.PythonClassImplementingIlumJob
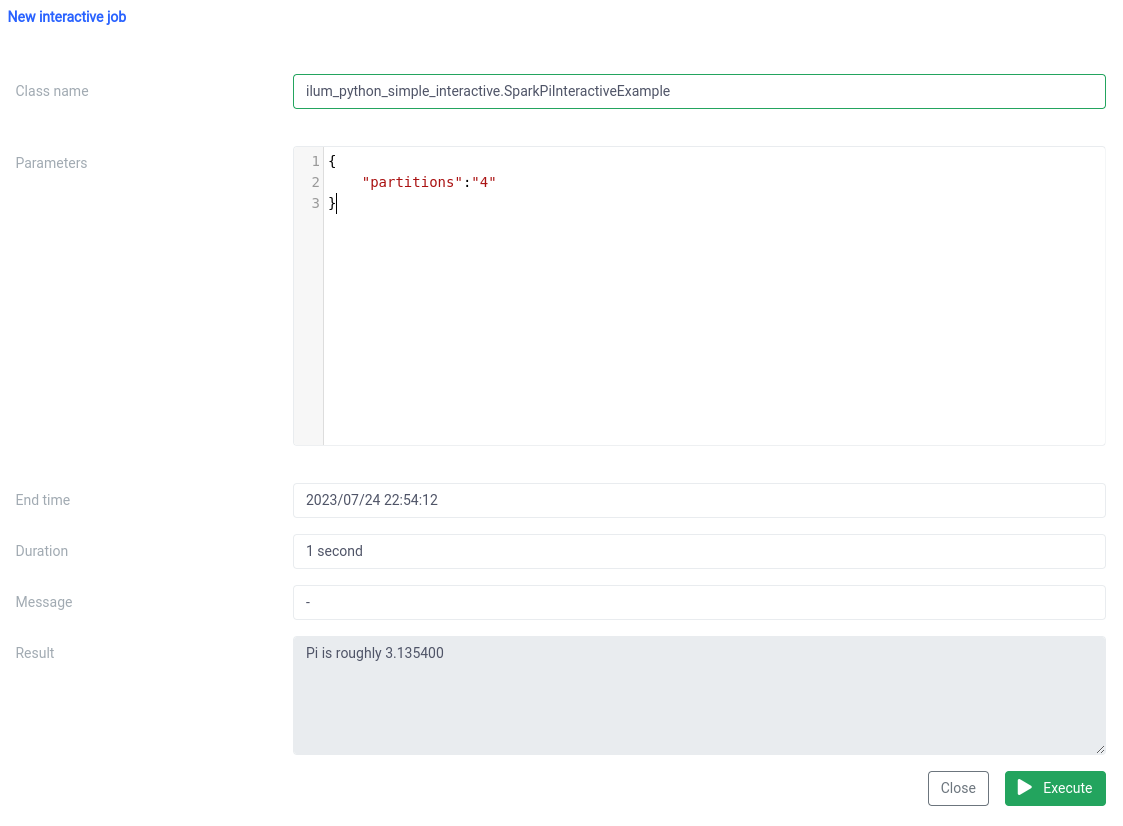
我们可以使用 应用程序接口 .
1. 创建群组
curl -X POST 'localhost:9888/api/v1/group' \
--form 'name=“SparkPiInteractiveExample”' \
--form 'kind=“JOB”' \
--form 'clusterName=“default”' \
--form 'pyFiles=@“/path/to/ilum_python_simple_interactive.py”' \
--form 'language=“PYTHON”' API 调用
{“groupId”:“20230726-1638-mjrw3”} 结果
2. 任务执行
curl -X POST 'localhost:9888/api/v1/group/20230726-1638-mjrw3/job/execute' \
-H '内容类型: application/json' \
-d '{ “jobClass”:“ilum_python_simple_interactive.SparkPiInteractiveExample“, ”jobConfig“: {”partitions“:”10“}, ”type“:”interactive_job_execute“}' API 调用
{
“jobInstanceId”:“20230726-1638-mjrw3-a1srahhu”,
“jobId”:“20230726-1638-mjrw3-wwt5a”,
“groupId”:“20230726-1638-mjrw3”,
“startTime”:1690390323154、
“endTime”:1690390325200,
“jobClass”:“ilum_python_simple_interactive 的SparkPiInteractiveExample“、
“jobConfig”:{
“partitions”:“10”
},
“result”:“圆周率大约是 3.149400”,
“error”:null
} 结果
2.2 使用 numpy 的作业示例。
让我们看看第二个示例。
from pyspark.sql import SparkSession
from pyspark.ml import 管道
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.classification import LogisticRegression
from ilum.api import IlumJob
类 LogisticRegressionJobExample(IlumJob):
def run(self, spark_session: SparkSession, config: dict) -> str:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True,
inferSchema=True)
categoricalColumns = ['性别', '合作伙伴', '家属', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', '技术支持', 'StreamingTV',
'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod']
阶段 = []
对于 categoricalColumns 中的 categoricalCol:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + “索引”)
阶段 += [stringIndexer]
label_stringIdx = StringIndexer(inputCol=“Churn”, outputCol=“label”)
阶段 += [label_stringIdx]
numericCols = ['老年人', '任期', '每月收费']
assemblerInputs = [c + categoricalColumns 中 c 的“索引”] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol=“features”)
阶段 += [汇编器]
管道 = 管道(stages=stages)
管道模型 = pipeline.fit(df)
df = pipelineModel.transform(df)
训练, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))],
seed=int(config.get('seed', '42')))
lr = LogisticRegression(featuresCol=“features”, labelCol=“label”, maxIter=int(config.get('maxIter', '5'))))
lrModel = lr.fit(train)
预测 = lrModel.transform(test)
return '{}'.format(predictions.select(“customerID”, “label”, “prediction”).limit(
int(config.get('rowLimit', '5'))).toJSON().collect()) 1. 我们将 job 包装在一个 class 中,就像前面的例子一样:
类 LogisticRegressionJobExample(IlumJob):
def run(self, spark_session: SparkSession, config: dict) -> str:
# Job logic 在这里 同样,作业逻辑封装在 跑 扩展类的 method IlumJob ,帮助 Ilum 高效地处理工作。
2. 所有参数,包括数据管道的参数(如文件路径和 Logistic Regression 超参数),都是从 配置 字典:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True, inferSchema=True)
train, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))], seed=int(config.get('seed', '42'))))
lr = LogisticRegression(featuresCol=“features”, labelCol=“label”, maxIter=int(config.get('maxIter', '5')))) 通过将所有参数集中在一个位置,Ilum 提供了一种统一、一致的方法来配置和调整作业。
作业的结果(而不是写入特定位置)以 JSON 字符串的形式返回:
返回 '{}'.format(predictions.select(“customerID”, “label”, “prediction”).limit(int(config.get('rowLimit', '5'))).toJSON().collect()) 这允许对作业结果进行更动态和灵活的处理,然后可以根据应用程序的需要进一步处理或通过 API 公开这些结果。
此代码完美地展示了我们如何将 PySpark 作业与 Ilum 无缝集成,以实现交互式、API 驱动的数据处理管道。从 Pi 近似等简单示例到 Logistic Regression 等更复杂的情况,Ilum 的交互式工作用途广泛、适应性强且高效。
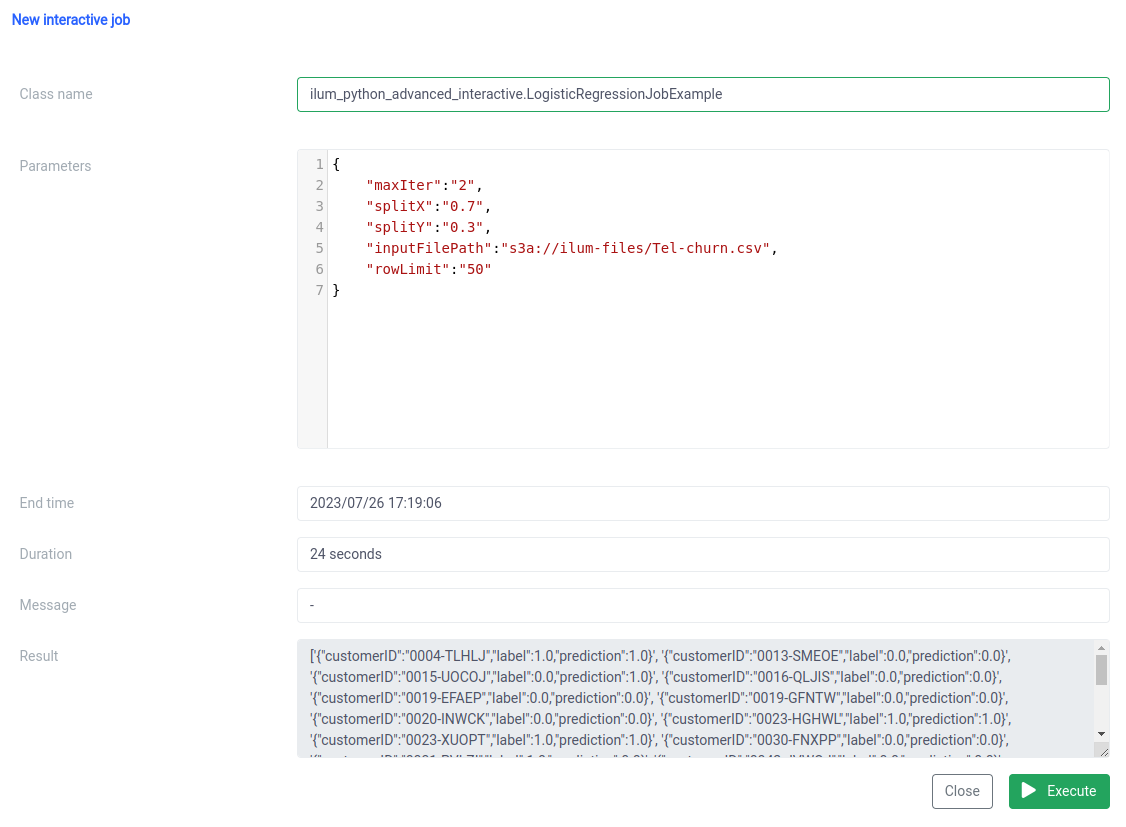
第 3 步:将 Spark 作业设为微服务
微服务带来了从传统整体式应用程序结构到更加模块化和敏捷的方法的范式转变。通过将复杂的应用程序分解为小型、松散耦合的服务,可以更轻松地根据特定要求独立构建、维护和扩展每个服务。当应用于我们的 Spark 作业时,这意味着我们可以创建一个强大的数据处理服务,该服务可以扩展、管理和更新,而不会影响我们应用程序堆栈的其他部分。
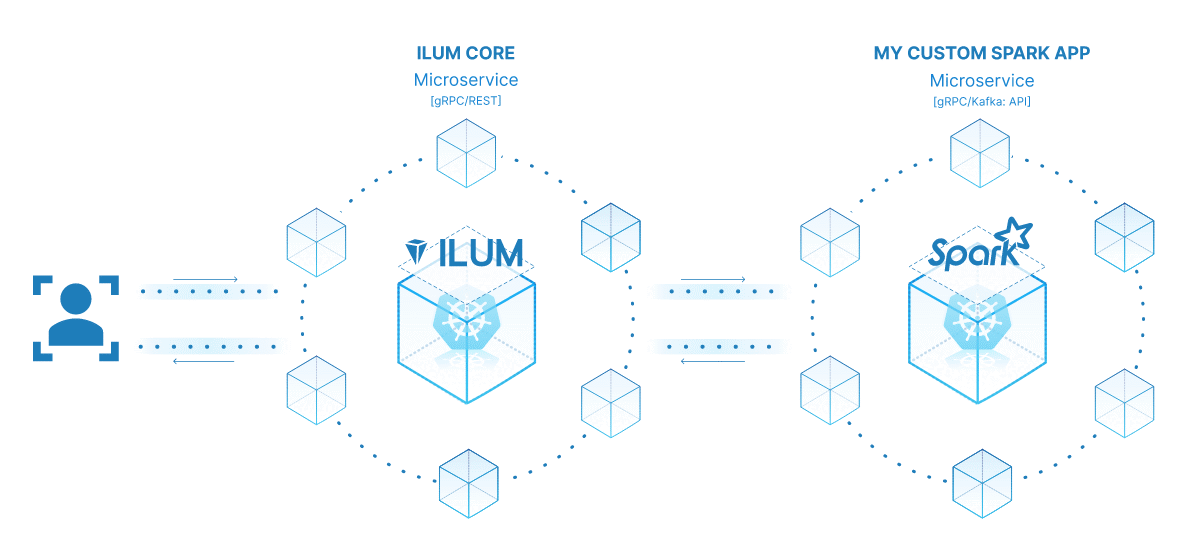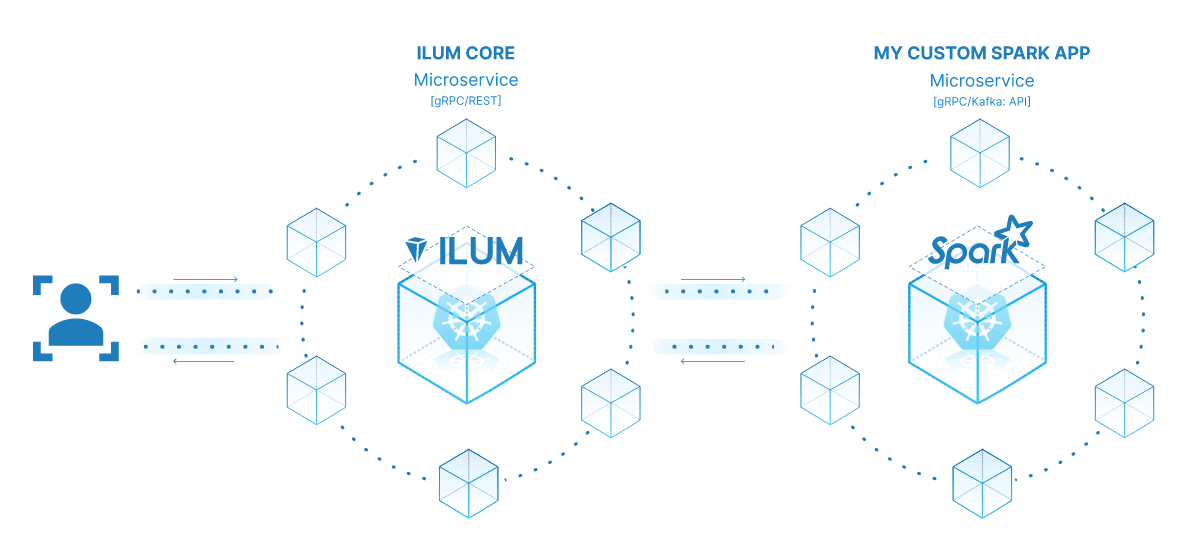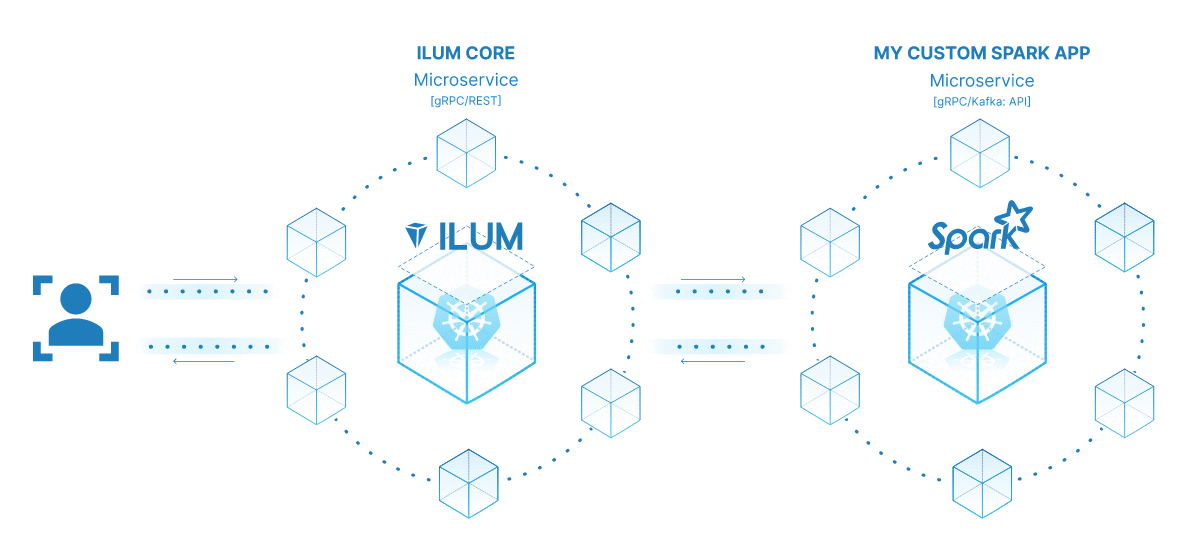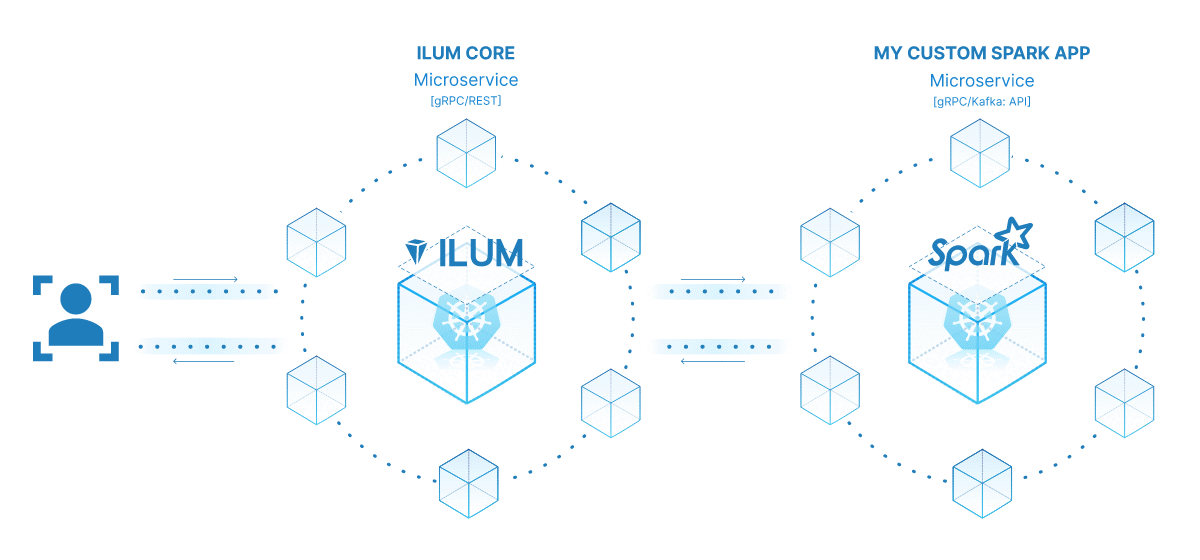
将 Spark 作业转换为微服务的强大之处在于其多功能性、可扩展性和实时交互功能。微服务是应用程序的可独立部署组件,作为单独的进程运行。它通过定义明确的 API 与其他组件通信,让您可以自由地独立设计、开发、部署和扩展每个微服务。
在 Ilum 的上下文中,可以将交互式 Spark 作业视为微服务。作业的 'run' 方法充当 API 端点。每次通过 Ilum 的 API 调用此方法时,您都会向此微服务发出请求。这为与 Spark 作业进行实时交互提供了可能性。
您可以从各种应用程序或脚本向微服务发出请求,获取数据并动态处理结果。此外,它还为围绕您的数据处理管道构建更复杂的面向服务的架构提供了机会。
此设置的一个关键优势是可扩展性。通过 Ilum UI 或 API,您可以根据负载或计算复杂性扩展或缩减作业(微服务)。您无需担心手动管理资源或负载均衡。Ilum 的内部负载均衡器将在 Spark 作业的实例之间分配 API 调用,确保高效的资源利用率。
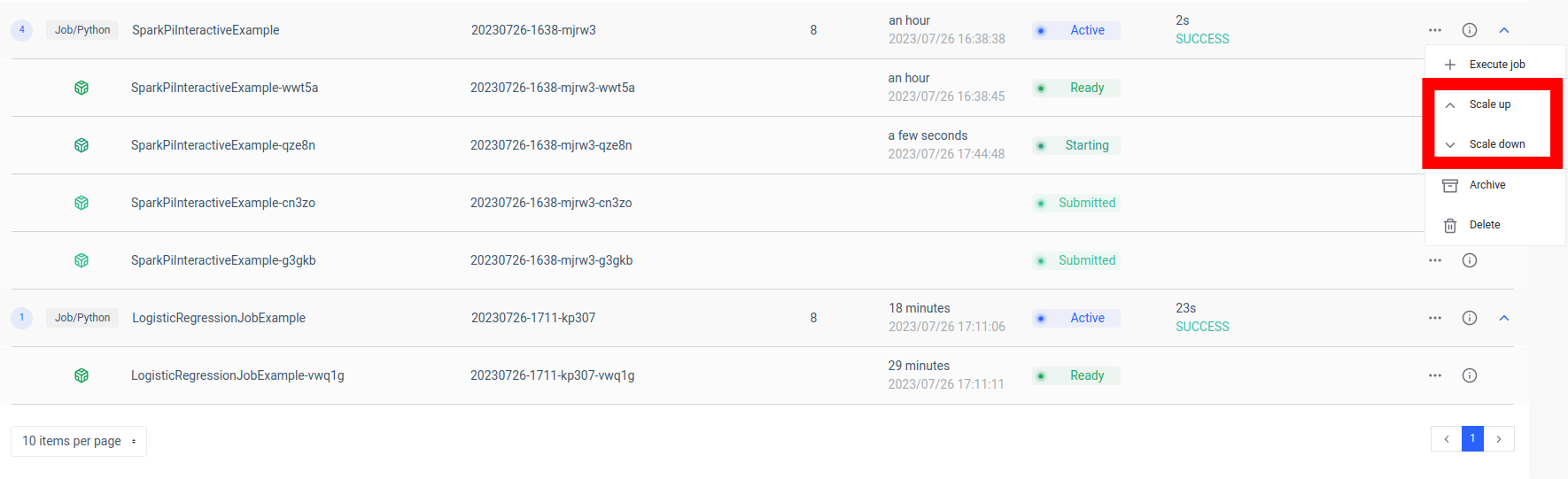
请记住,作业的实际处理时间取决于 Spark 作业的复杂程度和分配给它的资源。但是,借助 Kubernetes 提供的可扩展性,您可以随着作业需求的增长轻松扩展资源。
Ilum、Apache Spark 和微服务的这种组合带来了一种新的敏捷数据处理方式 - 高效、可扩展且响应迅速!

数据微服务架构中的游戏规则改变者
自从我们开始使用 Ilum 将简单的 Python Apache Spark 作业转换为成熟的微服务以来,我们已经走过了漫长的道路。我们看到了编写 Spark 作业、使其适应以交互模式工作并最终在 Ilum 强大的 API 的帮助下将其公开为微服务是多么容易。在此过程中,我们利用了 Python 的强大功能、Apache Spark 的功能以及 Ilum 的灵活性和可扩展性。这种结合不仅改变了我们的数据处理能力,还改变了我们对数据架构的看法。
旅程并不止于此。凭借对 Ilum 的全面 Python 支持,为数据处理和分析打开了一个充满可能性的新世界。随着我们继续构建和改进 Ilum,我们对 Python 为我们的平台带来的未来可能性感到兴奋。我们相信,随着 Python 和 Ilum 的结合,我们才刚刚开始重新定义数据微服务架构领域的可能性。
加入我们,踏上这段激动人心的旅程,让我们一起塑造数据处理的未来!